Data documentation¶
Introduction¶
The data documentation is based on small JSON-LD documents, each documenting a single resource. Examples of resources can be a dataset, an instrument, a sample, etc. All resources are uniquely identified by their IRI.
The primary focus of the tripper.dataset module is to document datasets such that they are consistent with the DCAT vocabulary, but at the same time easily extended additional semantic meaning provided by other ontologies. It is also easy to add and relate the datasets to other types of documents, like people, instruments and samples.
The tripper.dataset module provides a Python API for documenting resources at all four levels of data documentation, including:
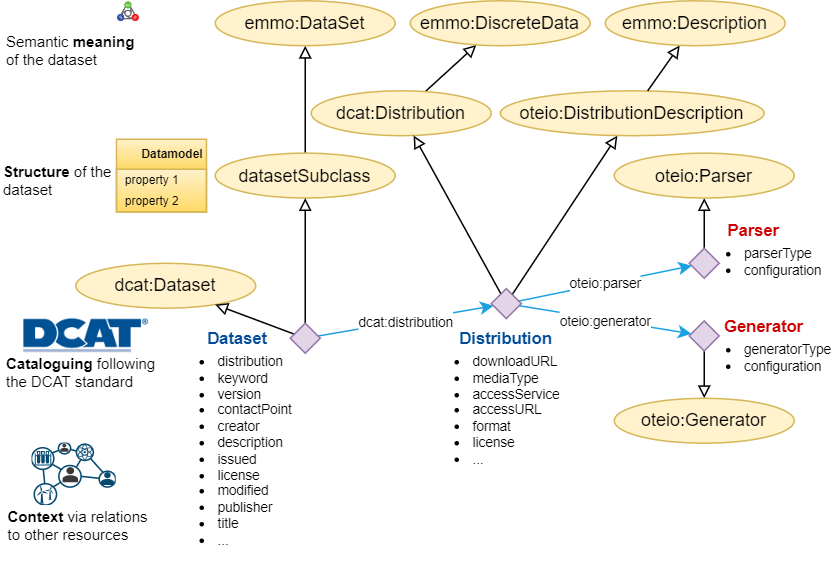
- Cataloguing: Storing and accessing documents based on their IRI and data properties. (Addressed FAIR aspects: findability and accessibility).
- Structural documentation: The structure of a dataset. Provided via DLite data models. (Addressed FAIR aspects: interoperability).
- Contextual documentation: Relations between resources, i.e. linked data. Enables contextual search. (Addressed FAIR aspects: findability and reusability).
- Semantic documentation: Describe what the resource is using ontologies. In combination with structural documentation, maps the properties of a data model to ontological concepts. (Addressed FAIR aspects: findability, interoperability and reusability).
The figure below shows illustrates how a dataset is documented in a triplestore.
Resource types¶
The tripper.dataset module include the following set of predefined resource types:
- dataset: Individual of dcat:Dataset and emmo:DataSet.
- distribution: Individual of dcat:Distribution.
- accessService: Individual of dcat:AccessService.
- generator: Individual of oteio:Generator.
- parser: Individual of oteio:Parser.
- resource: Any other documented resource, with no implicit type.
Future releases will support adding custom resource types.